Data Management Overview
In any data-driven project, effective management of data is crucial. This section provides essential techniques for handling and preparing data to ensure consistency, accuracy, and ease of analysis. From directory setup and data cleaning to advanced data processing, these methods form the backbone of reliable data management. Dive into the following topics to enhance your data handling capabilities and streamline your workflow.
Data Management Techniques
Path directories
Ensure that the directory exists. If not, create it.
- ensure_directory(path)
- Parameters:
path (str) – The path to the directory that needs to be ensured.
- Returns:
None
The ensure_directory function is a utility designed to facilitate the
management of directory paths within your project. When working with data
science projects, it is common to save and load data, images, and other
artifacts from specific directories. This function helps in making sure that
these directories exist before any read/write operations are performed. If
the specified directory does not exist, the function creates it. If it
already exists, it does nothing, thus preventing any errors related to
missing directories.
Implementation Example
In the example below, we demonstrate how to use the ensure_directory function
to verify and create directories as needed. This example sets up paths for data and
image directories, ensuring they exist before performing any operations that depend on them.
First, we define the base path as the parent directory of the current directory.
The os.pardir constant, equivalent to ".."", is used to navigate up one
directory level. Then, we define paths for the data directory and data output
directory, both located one level up from the current directory.
Next, we set paths for the PNG and SVG image directories, located within an
images folder in the parent directory. Using the ensure_directory
function, we then verify that these directories exist. If any of the specified
directories do not exist, the function creates them.
from eda_toolkit import ensure_directory
import os # import operating system for dir
base_path = os.path.join(os.pardir)
# Go up one level from 'notebooks' to parent directory,
# then into the 'data' folder
data_path = os.path.join(os.pardir, "data")
data_output = os.path.join(os.pardir, "data_output")
# create image paths
image_path_png = os.path.join(base_path, "images", "png_images")
image_path_svg = os.path.join(base_path, "images", "svg_images")
# Use the function to ensure'data' directory exists
ensure_directory(data_path)
ensure_directory(data_output)
ensure_directory(image_path_png)
ensure_directory(image_path_svg)
Output
Created directory: ../data
Created directory: ../data_output
Created directory: ../images/png_images
Created directory: ../images/svg_images
Adding Unique Identifiers
Add a column of unique IDs with a specified number of digits to the DataFrame.
- add_ids(df, id_colname='ID', num_digits=9, seed=None, set_as_index=False)
- Parameters:
df (pd.DataFrame) – The DataFrame to which IDs will be added.
id_colname (str, optional) – The name of the new column for the unique IDs. Defaults to
"ID".num_digits (int, optional) – The number of digits for the unique IDs. Defaults to
9. The first digit will always be non-zero to ensure proper formatting.seed (int, optional) – The seed for the random number generator to ensure reproducibility. Defaults to
None.set_as_index (bool, optional) – If
True, the generated ID column will replace the existing index of the DataFrame. Defaults toFalse.
- Returns:
The updated DataFrame with a new column of unique IDs. If
set_as_indexisTrue, the new ID column replaces the existing index.- Return type:
pd.DataFrame
- Raises:
ValueError – If the number of rows in the DataFrame exceeds the pool of possible unique IDs for the specified
num_digits.
Notes
The function ensures all IDs are unique by resolving potential collisions during generation, even for large datasets.
The total pool size of unique IDs is determined by \(9 \times 10^{(\text{num_digits} - 1)}\), since the first digit must be non-zero.
Warnings are printed if the number of rows in the DataFrame approaches the pool size of possible unique IDs, recommending increasing
num_digits.If
set_as_indexisFalse, the ID column will be added as the first column in the DataFrame.Setting a random seed ensures reproducibility of the generated IDs.
The add_ids function is used to append a column of unique identifiers with a
specified number of digits to a given dataframe. This is particularly useful for
creating unique patient or record IDs in datasets. The function allows you to
specify a custom column name for the IDs, the number of digits for each ID, and
optionally set a seed for the random number generator to ensure reproducibility.
Additionally, you can choose whether to set the new ID column as the index of the
dataframe.
Implementation Example
In the example below, we demonstrate how to use the add_ids function to add a
column of unique IDs to a dataframe. We start by importing the necessary libraries
and creating a sample dataframe. We then use the add_ids function to generate
and append a column of unique IDs with a specified number of digits to the dataframe.
First, we import the pandas library and the add_ids function from the eda_toolkit.
Then, we create a sample dataframe with some data. We call the add_ids function,
specifying the dataframe, the column name for the IDs, the number of digits for
each ID, a seed for reproducibility, and whether to set the new ID column as the
index. The function generates unique IDs for each row and adds them as the first
column in the dataframe.
from eda_toolkit import add_ids
# Add a column of unique IDs with 9 digits and call it "census_id"
df = add_ids(
df=df,
id_colname="census_id",
num_digits=9,
seed=111,
set_as_index=True,
)
Output
First 5 Rows of Census Income Data (Adapted from Kohavi, 1996, UCI Machine Learning Repository) [1]
DataFrame index is unique.
| age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | |
|---|---|---|---|---|---|---|---|---|
| census_id | ||||||||
| 582248222 | 39 | State-gov | 77516 | Bachelors | 13 | Never-married | Adm-clerical | Not-in-family |
| 561810758 | 50 | Self-emp-not-inc | 83311 | Bachelors | 13 | Married-civ-spouse | Exec-managerial | Husband |
| 598098459 | 38 | Private | 215646 | HS-grad | 9 | Divorced | Handlers-cleaners | Not-in-family |
| 776705221 | 53 | Private | 234721 | 11th | 7 | Married-civ-spouse | Handlers-cleaners | Husband |
| 479262902 | 28 | Private | 338409 | Bachelors | 13 | Married-civ-spouse | Prof-specialty | Wife |
Trailing Period Removal
Strip the trailing period from values in a specified column of a DataFrame, if present.
- strip_trailing_period(df, column_name)
- Parameters:
df (pd.DataFrame) – The DataFrame containing the column to be processed.
column_name (str) – The name of the column containing values with potential trailing periods.
- Returns:
The updated DataFrame with trailing periods removed from the specified column.
- Return type:
pd.DataFrame
- Raises:
ValueError – If the specified
column_namedoes not exist in the DataFrame, pandas will raise aValueError.
Notes:
For string values, trailing periods are stripped directly.
For numeric values represented as strings (e.g.,
"1234."), the trailing period is removed, and the value is converted back to a numeric type if possible.NaNvalues are preserved and remain unprocessed.Non-string and non-numeric types are returned as-is.
The strip_trailing_period function is designed to remove trailing periods
from float values in a specified column of a DataFrame. This can be particularly
useful when dealing with data that has been inconsistently formatted, ensuring
that all float values are correctly represented.
Implementation Example
In the example below, we demonstrate how to use the strip_trailing_period function to clean a
column in a DataFrame. We start by importing the necessary libraries and creating a sample DataFrame.
We then use the strip_trailing_period function to remove any trailing periods from the specified column.
from eda_toolkit import strip_trailing_period
# Create a sample dataframe with trailing periods in some values
data = {
"values": [1.0, 2.0, 3.0, 4.0, 5.0, 6.],
}
df = pd.DataFrame(data)
# Remove trailing periods from the 'values' column
df = strip_trailing_period(df=df, column_name="values")
Output
First 6 Rows of Data Before and After Removing Trailing Periods (Adapted from Example)
Before:
|
After:
|
Note
The last row shows 6 as an int with a trailing period with its conversion to float.
Standardized Dates
Parse and standardize date strings based on the provided rule.
- parse_date_with_rule(date_str)
This function takes a date string and standardizes it to the
ISO 8601format (YYYY-MM-DD). It assumes dates are provided in either day/month/year or month/day/year format. The function first checks if the first part of the date string (day or month) is greater than 12, which unambiguously indicates a day/month/year format. If the first part is 12 or less, the function attempts to parse the date as month/day/year, falling back to day/month/year if the former raises aValueErrordue to an impossible date (e.g., month being greater than 12).- Parameters:
date_str (str) – A date string to be standardized.
- Returns:
A standardized date string in the format
YYYY-MM-DD.- Return type:
- Raises:
ValueError – If
date_stris in an unrecognized format or if the function cannot parse the date.
Implementation Example
In the example below, we demonstrate how to use the parse_date_with_rule
function to standardize date strings. We start by importing the necessary library
and creating a sample list of date strings. We then use the parse_date_with_rule
function to parse and standardize each date string to the ISO 8601 format.
from eda_toolkit import parse_date_with_rule
date_strings = ["15/04/2021", "04/15/2021", "01/12/2020", "12/01/2020"]
standardized_dates = [parse_date_with_rule(date) for date in date_strings]
print(standardized_dates)
Output
['2021-04-15', '2021-04-15', '2020-12-01', '2020-01-12']
Important
In the next example, we demonstrate how to apply the parse_date_with_rule
function to a DataFrame column containing date strings using the .apply() method.
This is particularly useful when you need to standardize date formats across an
entire column in a DataFrame.
# Creating the DataFrame
data = {
"date_column": [
"31/12/2021",
"01/01/2022",
"12/31/2021",
"13/02/2022",
"07/04/2022",
],
"name": ["Alice", "Bob", "Charlie", "David", "Eve"],
"amount": [100.0, 150.5, 200.75, 250.25, 300.0],
}
df = pd.DataFrame(data)
# Apply the function to the DataFrame column
df["standardized_date"] = df["date_column"].apply(parse_date_with_rule)
print(df)
Output
date_column name amount standardized_date
0 31/12/2021 Alice 100.00 2021-12-31
1 01/01/2022 Bob 150.50 2022-01-01
2 12/31/2021 Charlie 200.75 2021-12-31
3 13/02/2022 David 250.25 2022-02-13
4 07/04/2022 Eve 300.00 2022-04-07
DataFrame Analysis
Analyze DataFrame columns, including data type, null values, and unique value counts.
The dataframe_columns function provides a comprehensive summary of a DataFrame’s columns, including information on data types, null values, unique values, and the most frequent values. It can output either a plain DataFrame for further processing or a styled DataFrame for visual presentation in Jupyter environments.
- dataframe_columns(df, background_color=None, return_df=False, sort_cols_alpha=False)
- Parameters:
df (pandas.DataFrame) – The DataFrame to analyze.
background_color (str, optional) – Hex color code or color name for background styling in the output DataFrame. Applies to specific columns, such as unique value totals and percentages. Defaults to
None.return_df (bool, optional) – If
True, returns the plain DataFrame with summary statistics. IfFalse, returns a styled DataFrame for visual presentation. Defaults toFalse.sort_cols_alpha (bool, optional) – If
True, sorts the DataFrame columns alphabetically in the output. Defaults toFalse.
- Returns:
If
return_dfisTrueor running in a terminal environment, returns the plain DataFrame containing column summary statistics.If
return_dfisFalseand running in a Jupyter Notebook, returns a styled DataFrame with optional background styling.
- Return type:
pandas.DataFrame
- Raises:
ValueError – If the DataFrame is empty or contains no columns.
Notes
Automatically detects whether the function is running in a Jupyter Notebook or terminal and adjusts the output accordingly.
In Jupyter environments, uses Pandas’ Styler for visual presentation. If the installed Pandas version does not support
hide, falls back tohide_index.Utilizes a
tqdmprogress bar to show the status of column processing.Preprocesses columns to handle NaN values and replaces empty strings with Pandas’
pd.NAfor consistency.
Census Income Example
In the example below, we demonstrate how to use the dataframe_columns
function to analyze a DataFrame’s columns. You may notice a new variable,
age_group, is introduced. The logic for generating this variable is provided here.
from eda_toolkit import dataframe_columns
dataframe_columns(df=df)
Output
Result on Census Income Data (Adapted from Kohavi, 1996, UCI Machine Learning Repository) [1]
Shape: (48842, 16)
Total seconds of processing time: 0.861555
| column | dtype | null_total | null_pct | unique_values_total | max_unique_value | max_unique_value_total | max_unique_value_pct | |
|---|---|---|---|---|---|---|---|---|
| 0 | age | int64 | 0 | 0 | 74 | 36 | 1348 | 2.76 |
| 1 | workclass | object | 963 | 1.97 | 9 | Private | 33906 | 69.42 |
| 2 | fnlwgt | int64 | 0 | 0 | 28523 | 203488 | 21 | 0.04 |
| 3 | education | object | 0 | 0 | 16 | HS-grad | 15784 | 32.32 |
| 4 | education-num | int64 | 0 | 0 | 16 | 9 | 15784 | 32.32 |
| 5 | marital-status | object | 0 | 0 | 7 | Married-civ-spouse | 22379 | 45.82 |
| 6 | occupation | object | 966 | 1.98 | 15 | Prof-specialty | 6172 | 12.64 |
| 7 | relationship | object | 0 | 0 | 6 | Husband | 19716 | 40.37 |
| 8 | race | object | 0 | 0 | 5 | White | 41762 | 85.5 |
| 9 | sex | object | 0 | 0 | 2 | Male | 32650 | 66.85 |
| 10 | capital-gain | int64 | 0 | 0 | 123 | 0 | 44807 | 91.74 |
| 11 | capital-loss | int64 | 0 | 0 | 99 | 0 | 46560 | 95.33 |
| 12 | hours-per-week | int64 | 0 | 0 | 96 | 40 | 22803 | 46.69 |
| 13 | native-country | object | 274 | 0.56 | 42 | United-States | 43832 | 89.74 |
| 14 | income | object | 0 | 0 | 4 | <=50K | 24720 | 50.61 |
| 15 | age_group | category | 0 | 0 | 9 | 18-29 | 13920 | 28.5 |
DataFrame Column Names
unique_values_totalThis column indicates the total number of unique values present in each column of the DataFrame. It measures the distinct values that a column holds. For example, in the
agecolumn, there are 74 unique values, meaning the ages vary across 74 distinct entries.max_unique_valueThis column shows the most frequently occurring value in each column. For example, in the
workclasscolumn, the most common value isPrivate, indicating that this employment type is the most represented in the dataset. For numeric columns likecapital-gainandcapital-loss, the most common value is0, which suggests that the majority of individuals have no capital gain or loss.max_unique_value_totalThis represents the count of the most frequently occurring value in each column. For instance, in the
native-countrycolumn, the valueUnited-Statesappears43,832times, indicating that the majority of individuals in the dataset are from the United States.max_unique_value_pctThis column shows the percentage that the most frequent value constitutes of the total number of rows. For example, in the
racecolumn, the valueWhitemakes up85.5%of the data, suggesting a significant majority of the dataset belongs to this racial group.
Calculation Details
unique_values_totalis calculated using thenunique()function, which counts the number of unique values in a column.max_unique_valueis determined by finding the value with the highest frequency usingvalue_counts(). For string columns, any missing values (if present) are replaced with the string"null"before computing the frequency.max_unique_value_totalis the frequency count of themax_unique_value.max_unique_value_pctis the percentage ofmax_unique_value_totaldivided by the total number of rows in the DataFrame, providing an idea of how dominant the most frequent value is.
This analysis helps in identifying columns with a high proportion of dominant values, like <=50K in the income column, which appears 24,720 times, making up 50.61% of the entries. This insight can be useful for understanding data distributions, identifying potential data imbalances, or even spotting opportunities for feature engineering in further data processing steps.
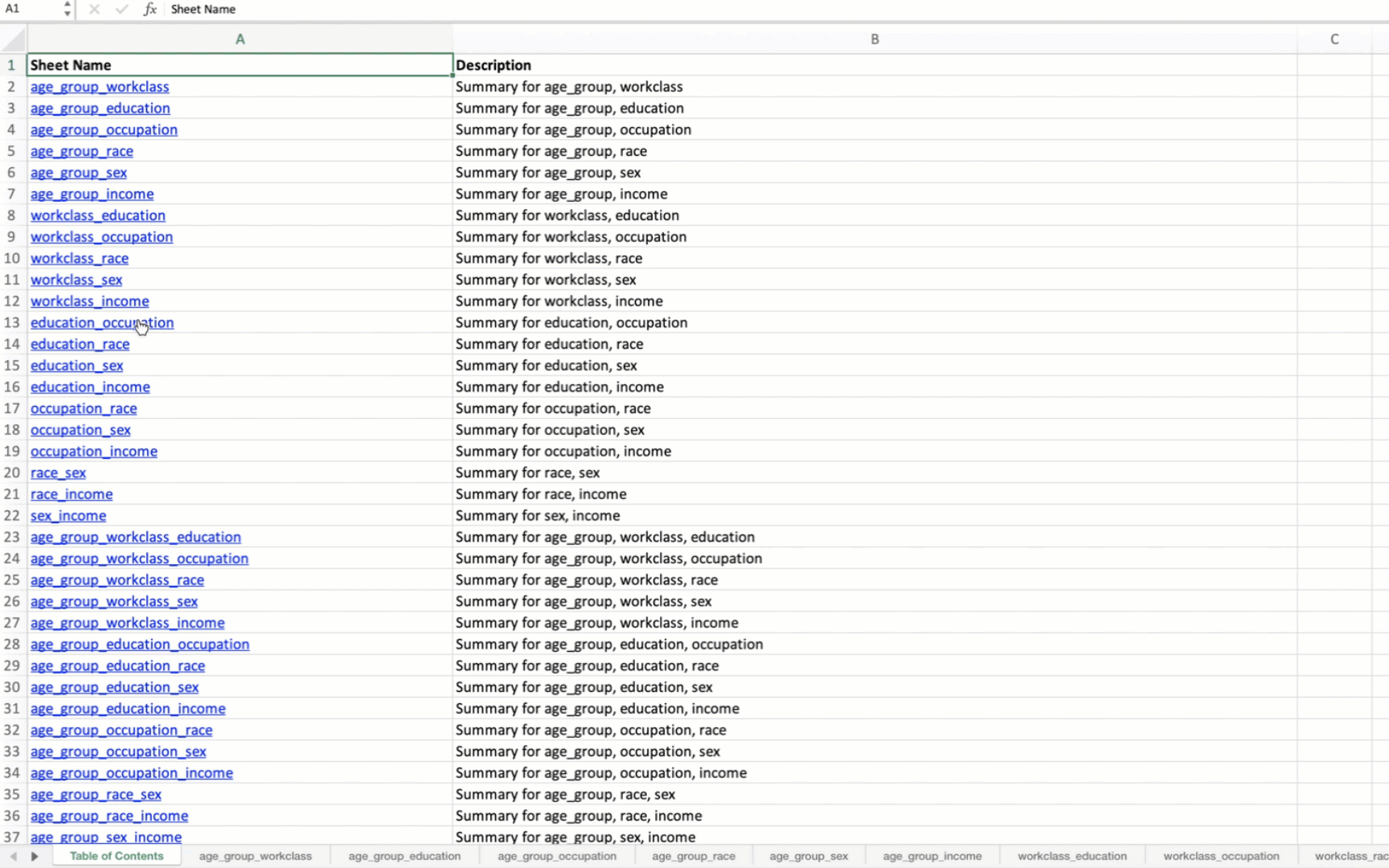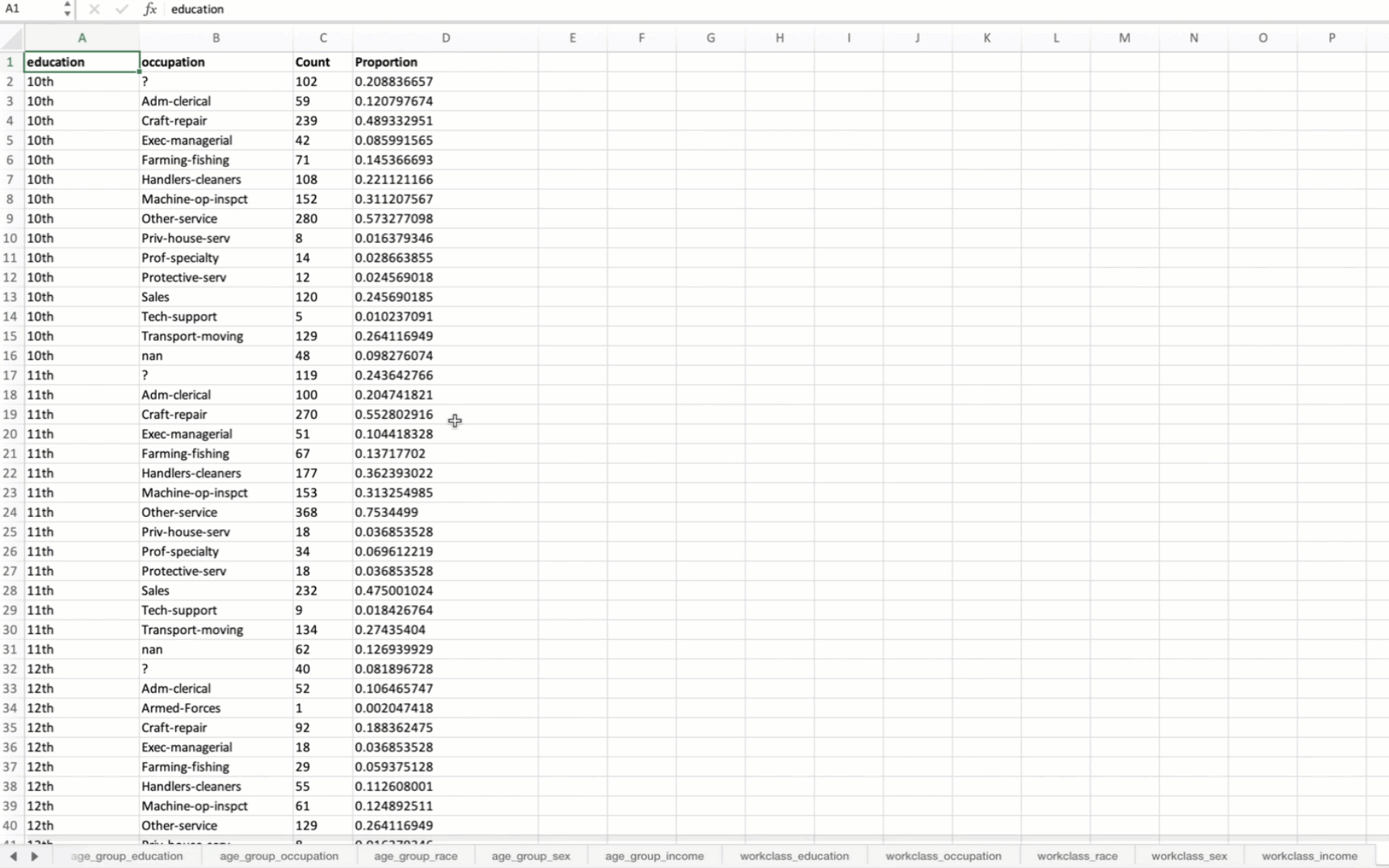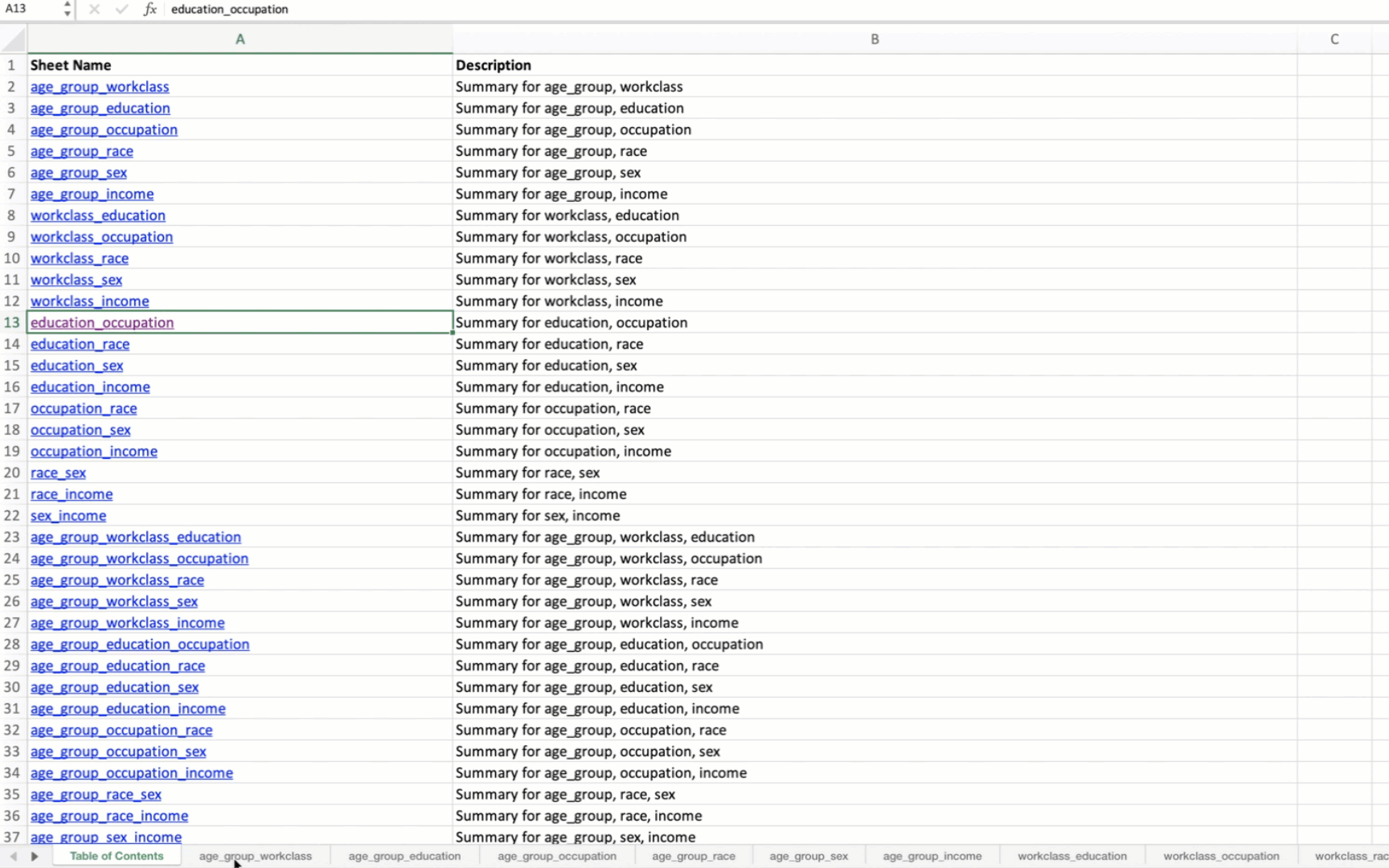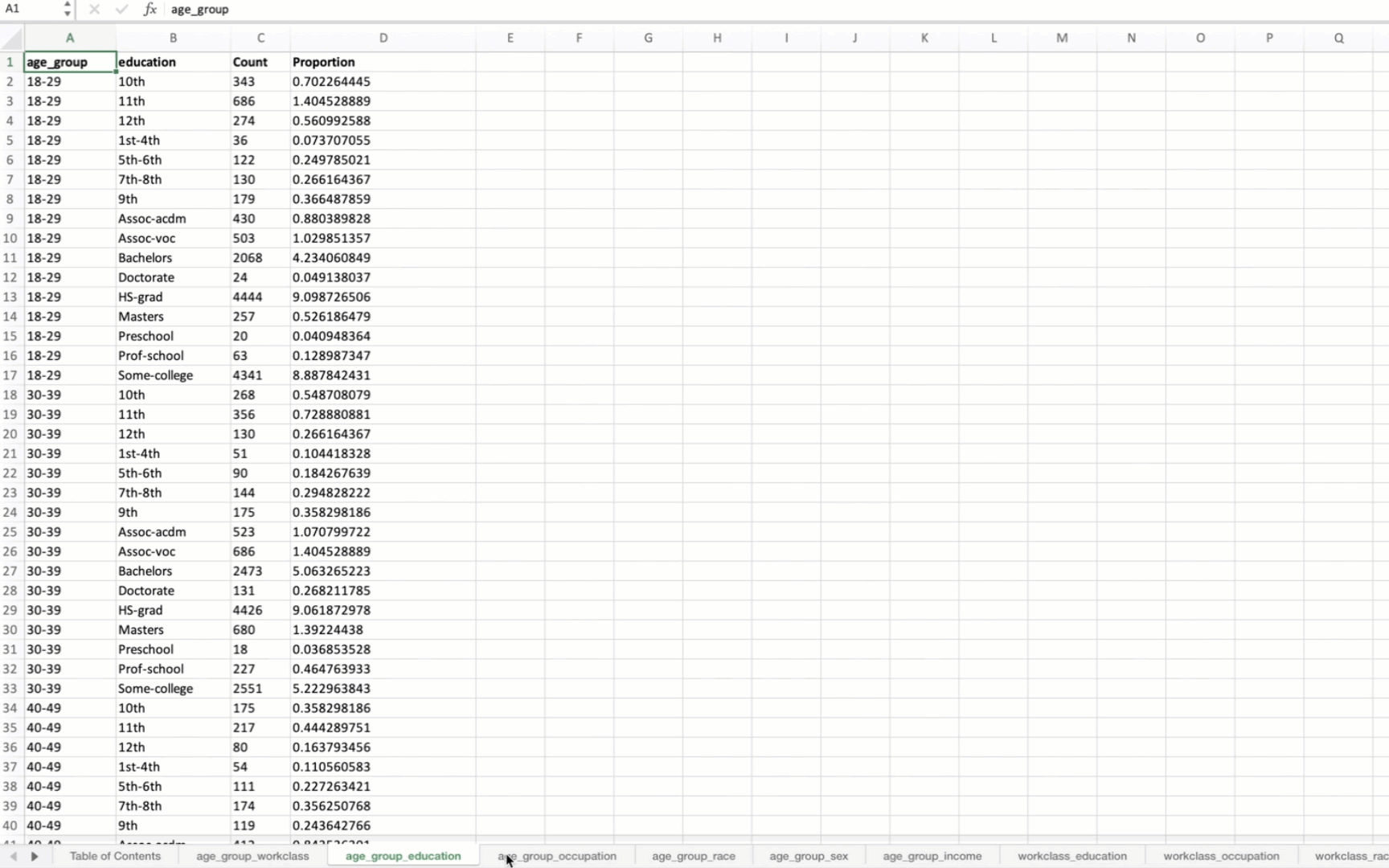
Generating Summary Tables for Variable Combinations
Generate and save summary tables for all possible combinations of specified variables in a DataFrame to an Excel file, complete with formatting and progress tracking.
- summarize_all_combinations(df, variables, data_path, data_name, min_length=2)
Generate summary tables for all possible combinations of the specified variables in the DataFrame and save them to an Excel file with a Table of Contents.
- Parameters:
df (pandas.DataFrame) – The pandas DataFrame containing the data.
variables (list of str) – List of column names from the DataFrame to generate combinations.
data_path (str) – Directory path where the output Excel file will be saved.
data_name (str) – Name of the output Excel file.
min_length (int, optional) – Minimum size of the combinations to generate. Defaults to
2.
- Returns:
A tuple containing: - A dictionary where keys are tuples of column names (combinations) and values are the corresponding summary DataFrames. - A list of all generated combinations, where each combination is represented as a tuple of column names.
- Return type:
Notes
- Excel Output:
Each combination is saved as a separate sheet in an Excel file.
A “Table of Contents” sheet is created with hyperlinks to each combination’s summary table.
Sheet names are truncated to 31 characters to meet Excel’s constraints.
- Formatting:
Headers in all sheets are bold, left-aligned, and borderless.
Columns are auto-fitted to content length for improved readability.
A left-aligned format is applied to all columns in the output.
- The function uses
tqdmprogress bars for tracking: Combination generation.
Writing the Table of Contents.
Writing individual summary tables to Excel.
- The function uses
The function returns two outputs:
1.
summary_tables: A dictionary where each key is a tuple representing a combination of variables, and each value is a DataFrame containing the summary table for that combination. Each summary table includes the count and proportion of occurrences for each unique combination of values.2.
all_combinations: A list of all generated combinations of the specified variables. This is useful for understanding which combinations were analyzed and included in the summary tables.
Implementation Example
Below, we use the summarize_all_combinations function to generate summary tables for the specified
variables from a DataFrame containing the census data [1].
Note
Before proceeding with any further examples in this documentation, ensure that the age variable is binned into a new variable, age_group.
Detailed instructions for this process can be found under Binning Numerical Columns.
from eda_toolkit import summarize_all_combinations
# Define unique variables for the analysis
unique_vars = [
"age_group",
"workclass",
"education",
"occupation",
"race",
"sex",
"income",
]
# Generate summary tables for all combinations of the specified variables
summary_tables, all_combinations = summarize_all_combinations(
df=df,
data_path=data_output,
variables=unique_vars,
data_name="census_summary_tables.xlsx",
)
# Print all combinations of variables
print(all_combinations)
Output
[('age_group', 'workclass'),
('age_group', 'education'),
('age_group', 'occupation'),
('age_group', 'race'),
('age_group', 'sex'),
('age_group', 'income'),
('workclass', 'education'),
('workclass', 'occupation'),
('workclass', 'race'),
('workclass', 'sex'),
('workclass', 'income'),
('education', 'occupation'),
('education', 'race'),
('education', 'sex'),
('education', 'income'),
('occupation', 'race'),
('occupation', 'sex'),
('occupation', 'income'),
('race', 'sex'),
('race', 'income'),
('sex', 'income'),
('age_group', 'workclass', 'education'),
('age_group', 'workclass', 'occupation'),
('age_group', 'workclass', 'race'),
('age_group', 'workclass', 'sex'),
('age_group', 'workclass', 'income'),
('age_group', 'education', 'occupation'),
('age_group', 'education', 'race'),
('age_group', 'education', 'sex'),
('age_group', 'education', 'income'),
('age_group', 'occupation', 'race'),
('age_group', 'occupation', 'sex'),
('age_group', 'occupation', 'income'),
('age_group', 'race', 'sex'),
('age_group', 'race', 'income'),
('age_group', 'sex', 'income'),
('workclass', 'education', 'occupation'),
('workclass', 'education', 'race'),
('workclass', 'education', 'sex'),
('workclass', 'education', 'income'),
('workclass', 'occupation', 'race'),
('workclass', 'occupation', 'sex'),
('workclass', 'occupation', 'income'),
('workclass', 'race', 'sex'),
('workclass', 'race', 'income'),
('workclass', 'sex', 'income'),
('education', 'occupation', 'race'),
('education', 'occupation', 'sex'),
('education', 'occupation', 'income'),
('education', 'race', 'sex'),
('education', 'race', 'income'),
('education', 'sex', 'income'),
('occupation', 'race', 'sex'),
('occupation', 'race', 'income'),
('occupation', 'sex', 'income'),
('race', 'sex', 'income'),
('age_group', 'workclass', 'education', 'occupation'),
('age_group', 'workclass', 'education', 'race'),
('age_group', 'workclass', 'education', 'sex'),
('age_group', 'workclass', 'education', 'income'),
('age_group', 'workclass', 'occupation', 'race'),
('age_group', 'workclass', 'occupation', 'sex'),
('age_group', 'workclass', 'occupation', 'income'),
('age_group', 'workclass', 'race', 'sex'),
('age_group', 'workclass', 'race', 'income'),
('age_group', 'workclass', 'sex', 'income'),
('age_group', 'education', 'occupation', 'race'),
('age_group', 'education', 'occupation', 'sex'),
('age_group', 'education', 'occupation', 'income'),
('age_group', 'education', 'race', 'sex'),
('age_group', 'education', 'race', 'income'),
('age_group', 'education', 'sex', 'income'),
('age_group', 'occupation', 'race', 'sex'),
('age_group', 'occupation', 'race', 'income'),
('age_group', 'occupation', 'sex', 'income'),
('age_group', 'race', 'sex', 'income'),
('workclass', 'education', 'occupation', 'race'),
('workclass', 'education', 'occupation', 'sex'),
('workclass', 'education', 'occupation', 'income'),
('workclass', 'education', 'race', 'sex'),
('workclass', 'education', 'race', 'income'),
('workclass', 'education', 'sex', 'income'),
('workclass', 'occupation', 'race', 'sex'),
('workclass', 'occupation', 'race', 'income'),
('workclass', 'occupation', 'sex', 'income'),
('workclass', 'race', 'sex', 'income'),
('education', 'occupation', 'race', 'sex'),
('education', 'occupation', 'race', 'income'),
('education', 'occupation', 'sex', 'income'),
('education', 'race', 'sex', 'income'),
('occupation', 'race', 'sex', 'income'),
('age_group', 'workclass', 'education', 'occupation', 'race'),
('age_group', 'workclass', 'education', 'occupation', 'sex'),
('age_group', 'workclass', 'education', 'occupation', 'income'),
('age_group', 'workclass', 'education', 'race', 'sex'),
('age_group', 'workclass', 'education', 'race', 'income'),
('age_group', 'workclass', 'education', 'sex', 'income'),
('age_group', 'workclass', 'occupation', 'race', 'sex'),
('age_group', 'workclass', 'occupation', 'race', 'income'),
('age_group', 'workclass', 'occupation', 'sex', 'income'),
('age_group', 'workclass', 'race', 'sex', 'income'),
('age_group', 'education', 'occupation', 'race', 'sex'),
('age_group', 'education', 'occupation', 'race', 'income'),
('age_group', 'education', 'occupation', 'sex', 'income'),
('age_group', 'education', 'race', 'sex', 'income'),
('age_group', 'occupation', 'race', 'sex', 'income'),
('workclass', 'education', 'occupation', 'race', 'sex'),
('workclass', 'education', 'occupation', 'race', 'income'),
('workclass', 'education', 'occupation', 'sex', 'income'),
('workclass', 'education', 'race', 'sex', 'income'),
('workclass', 'occupation', 'race', 'sex', 'income'),
('education', 'occupation', 'race', 'sex', 'income'),
('age_group', 'workclass', 'education', 'occupation', 'race', 'sex'),
('age_group', 'workclass', 'education', 'occupation', 'race', 'income'),
('age_group', 'workclass', 'education', 'occupation', 'sex', 'income'),
('age_group', 'workclass', 'education', 'race', 'sex', 'income'),
('age_group', 'workclass', 'occupation', 'race', 'sex', 'income'),
('age_group', 'education', 'occupation', 'race', 'sex', 'income'),
('workclass', 'education', 'occupation', 'race', 'sex', 'income'),
('age_group',
'workclass',
'education',
'occupation',
'race',
'sex',
'income')]
When applied to the US Census data, the output Excel file will contain summary tables for all possible combinations of the specified variables. The first sheet will be a Table of Contents with hyperlinks to each summary table.
Saving DataFrames to Excel with Customized Formatting
Save multiple DataFrames to separate sheets in an Excel file with progress tracking and formatting.
This section explains how to save multiple DataFrames to separate sheets in an
Excel file with customized formatting using the save_dataframes_to_excel function.
- save_dataframes_to_excel(file_path, df_dict, decimal_places=0)
Save DataFrames to an Excel file, applying formatting and autofitting columns.
Notes
Progress Tracking: The function uses
tqdmto display a progress bar while saving DataFrames to Excel sheets.- Column Formatting:
Columns are autofitted to content length and left-aligned by default.
Numeric columns are rounded to the specified decimal places and formatted accordingly.
Non-numeric columns are left-aligned.
- Header Styling:
Headers are bold, left-aligned, and borderless.
Dependencies: This function requires the
xlsxwriterlibrary.
The function performs the following tasks:
Writes each DataFrame to its respective sheet in the Excel file.
Rounds numeric columns to the specified number of decimal places.
Applies customized formatting to headers and cells.
Autofits columns based on content length for improved readability.
Tracks the saving process with a progress bar, making it user-friendly for large datasets.
Implementation Example
Below, we use the save_dataframes_to_excel function to save two DataFrames:
the original DataFrame and a filtered DataFrame with ages between 18 and 40.
from eda_toolkit import save_dataframes_to_excel
file_name = "df_census.xlsx" # Name of the output Excel file
file_path = os.path.join(data_path, file_name)
# filter DataFrame to Ages 18-40
filtered_df = df[(df["age"] > 18) & (df["age"] < 40)]
df_dict = {
"original_df": df,
"ages_18_to_40": filtered_df,
}
save_dataframes_to_excel(
file_path=file_path,
df_dict=df_dict,
decimal_places=0,
)
Output
The output Excel file will contain the original DataFrame and a filtered DataFrame as a separate tab with ages between 18 and 40, each on separate sheets with customized formatting.
Creating Contingency Tables
Create a contingency table from one or more columns in a DataFrame, with sorting options.
This section explains how to create contingency tables from one or more columns in a DataFrame, with options to sort the results using the contingency_table function.
- contingency_table(df, cols=None, sort_by=0)
- Parameters:
df (pandas.DataFrame) – The DataFrame to analyze.
cols (str or list of str, optional) – Name of the column (as a string) for a single column or list of column names for multiple columns. Must provide at least one column.
sort_by (int, optional) – Enter
0to sort results by column groups; enter1to sort results by totals in descending order. Defaults to0.
- Raises:
ValueError – If no columns are specified or if
sort_byis not0or1.- Returns:
A DataFrame containing the contingency table with the specified columns, a
'Total'column representing the count of occurrences, and a'Percentage'column representing the percentage of the total count.- Return type:
pandas.DataFrame
Implementation Example
Below, we use the contingency_table function to create a contingency table
from the specified columns in a DataFrame containing census data [1]
from eda_toolkit import contingency_table
contingency_table(
df=df,
cols=[
"age_group",
"workclass",
"race",
"sex",
],
sort_by=1,
)
Note
You may notice a new variable, age_group, is introduced. The logic for
generating this variable is provided here.
Output
The output will be a contingency table with the specified columns, showing the
total counts and percentages of occurrences for each combination of values. The
table will be sorted by the 'Total' column in descending order because sort_by
is set to 1.
age_group workclass race sex Total Percentage
0 30-39 Private White Male 5856 11.99
1 18-29 Private White Male 5623 11.51
2 40-49 Private White Male 4267 8.74
3 18-29 Private White Female 3680 7.53
4 50-59 Private White Male 2565 5.25
.. ... ... ... ... ... ...
467 50-59 Federal-gov Other Male 1 0.00
468 50-59 Local-gov Asian-Pac-Islander Female 1 0.00
469 70-79 Self-emp-inc Black Male 1 0.00
470 80-89 Local-gov Asian-Pac-Islander Male 1 0.00
471 48842 100.00
[472 rows x 6 columns]
Highlighting Specific Columns in a DataFrame
This section explains how to highlight specific columns in a DataFrame using the highlight_columns function.
Highlight specific columns in a DataFrame with a specified background color.
- highlight_columns(df, columns, color='yellow')
- Parameters:
- Returns:
A Styler object with the specified columns highlighted.
- Return type:
pandas.io.formats.style.Styler
Implementation Example
Below, we use the highlight_columns function to highlight the age and education
columns in the first 5 rows of the census [1] DataFrame with a pink background color.
from eda_toolkit import highlight_columns
highlighted_df = highlight_columns(
df=df.head(),
columns=["age", "education"],
color="#F8C5C8",
)
highlighted_df
Output
The output will be a DataFrame with the specified columns highlighted in the given background color.
The age and education columns will be highlighted in pink.
The resulting styled DataFrame can be displayed in a Jupyter Notebook or saved to an
HTML file using the .render() method of the Styler object.
| age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | |
|---|---|---|---|---|---|---|---|---|
| census_id | ||||||||
| 582248222 | 39 | State-gov | 77516 | Bachelors | 13 | Never-married | Adm-clerical | Not-in-family |
| 561810758 | 50 | Self-emp-not-inc | 83311 | Bachelors | 13 | Married-civ-spouse | Exec-managerial | Husband |
| 598098459 | 38 | Private | 215646 | HS-grad | 9 | Divorced | Handlers-cleaners | Not-in-family |
| 776705221 | 53 | Private | 234721 | 11th | 7 | Married-civ-spouse | Handlers-cleaners | Husband |
| 479262902 | 28 | Private | 338409 | Bachelors | 13 | Married-civ-spouse | Prof-specialty | Wife |
Binning Numerical Columns
Binning numerical columns is a technique used to convert continuous numerical data into discrete categories or “bins.” This is especially useful for simplifying analysis, creating categorical features from numerical data, or visualizing the distribution of data within specific ranges. The process of binning involves dividing a continuous range of values into a series of intervals, or “bins,” and then assigning each value to one of these intervals.
Note
The code snippets below create age bins and assign a corresponding age group
label to each age in the DataFrame. The pd.cut function from pandas is used to
categorize the ages and assign them to a new column, age_group. Adjust the bins
and labels as needed for your specific data.
Below, we use the age column of the census data [1] from the UCI Machine Learning Repository as an example:
Bins Definition: The bins are defined by specifying the boundaries of each interval. For example, in the code snippet below, the
bin_ageslist specifies the boundaries for age groups:bin_ages = [ 0, 18, 30, 40, 50, 60, 70, 80, 90, 100, float("inf"), ]
Each pair of consecutive elements in
bin_agesdefines a bin. For example:The first bin is
[0, 18),The second bin is
[18, 30),and so on.
Labels for Bins: The label_ages list provides labels corresponding to each bin:
label_ages = [ "< 18", "18-29", "30-39", "40-49", "50-59", "60-69", "70-79", "80-89", "90-99", "100 +", ]
These labels are used to categorize the numerical values into meaningful groups.
Applying the Binning: The pd.cut function from Pandas is used to apply the binning process. For each value in the
agecolumn of the DataFrame, it assigns a corresponding label based on which bin the value falls into. Here,right=Falseindicates that each bin includes the left endpoint but excludes the right endpoint. For example, ifbin_ages = [0, 10, 20, 30], then a value of10will fall into the bin[10, 20)and be labeled accordingly.df["age_group"] = pd.cut( df["age"], bins=bin_ages, labels=label_ages, right=False, )
Mathematically, for a given value x in the
agecolumn:\[\begin{split}\text{age_group} = \begin{cases} < 18 & \text{if } 0 \leq x < 18 \\ 18-29 & \text{if } 18 \leq x < 30 \\ \vdots \\ 100 + & \text{if } x \geq 100 \end{cases}\end{split}\]The parameter
right=Falseinpd.cutmeans that the bins are left-inclusive and right-exclusive, except for the last bin, which is always right-inclusive when the upper bound is infinity (float("inf")).